There is an update on the blog post “vRealize Log Insight persistent static route on second network interface on behalf of Log Forwarding”. Beginning with version Aria Operations for Logs 8.14, the VAME_CONF_NET is no longer available, it’s removed in this version.
The information in the orignal blog post can still be used. Only now you need to manually create and predefine the 10-eth1.network configuration. See example at the bottom of the original post.
There are two important things to consider:
- Keep in mind that multic-nic configurations in Aria Ops for Logs is not officially supported
- After every update the 2nd interface must be recreated and configured again
Orginal post:
Recently I wanted to test whether it is possible to configure vRealize Log Insight (vRLI) log forwarding to a second network interface to reach a log target in another network segment that could not be reached from the default vRLI appliance ip address.
The first step is adding a second network interface to the appliance. In this example we use the following network configuration.
- VMnic1
Vlan10, IP 10.1.1.10, Subnetmask 255.255.255.0, Gateway 10.1.1.1 - VMnic2
Vlan20, IP 20.2.2.20, Subnetmask 255.255.255.0, Gateway 20.2.2.1 - In this example the log forwarding target ip address is 30.3.3.233
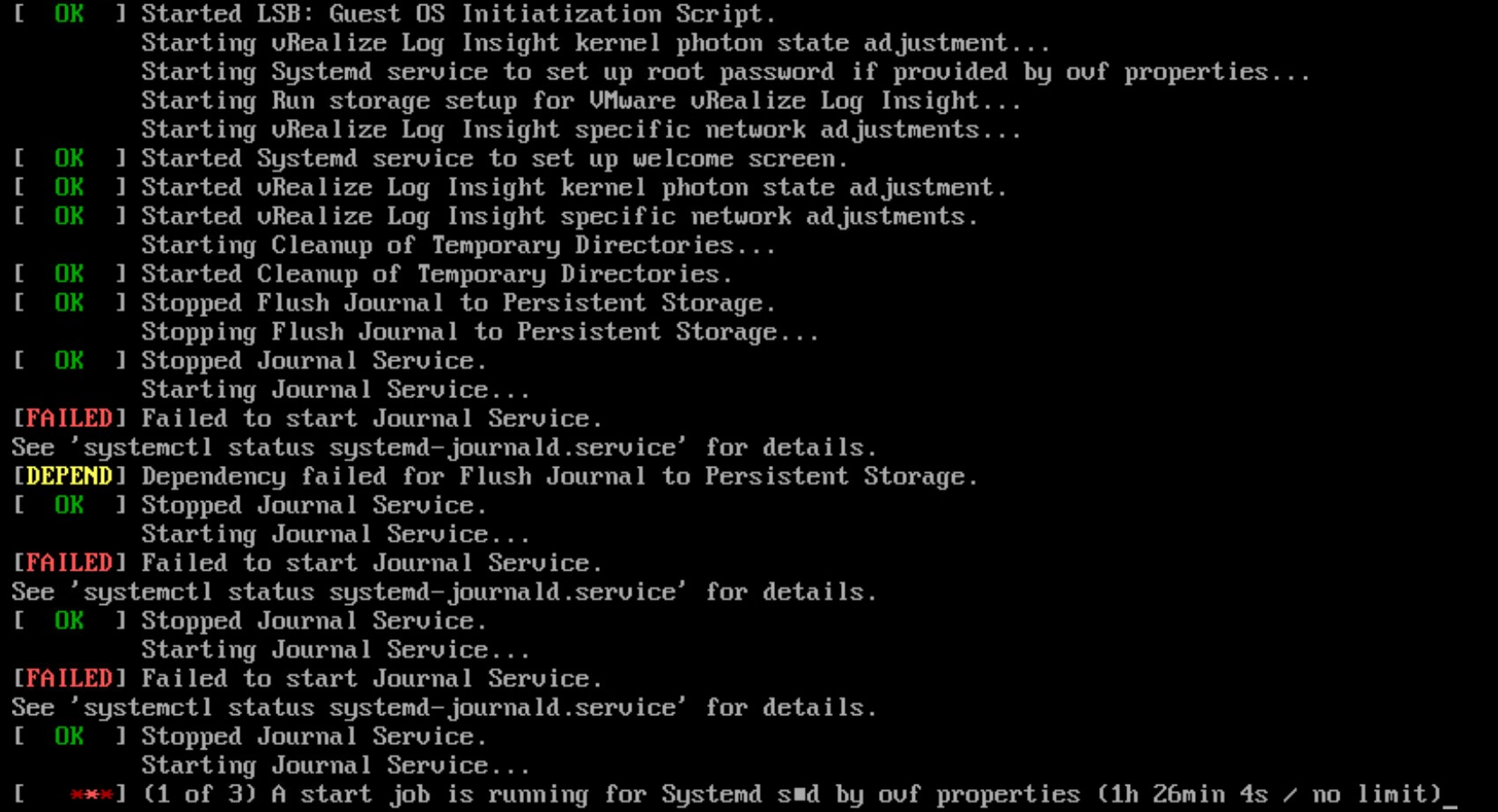
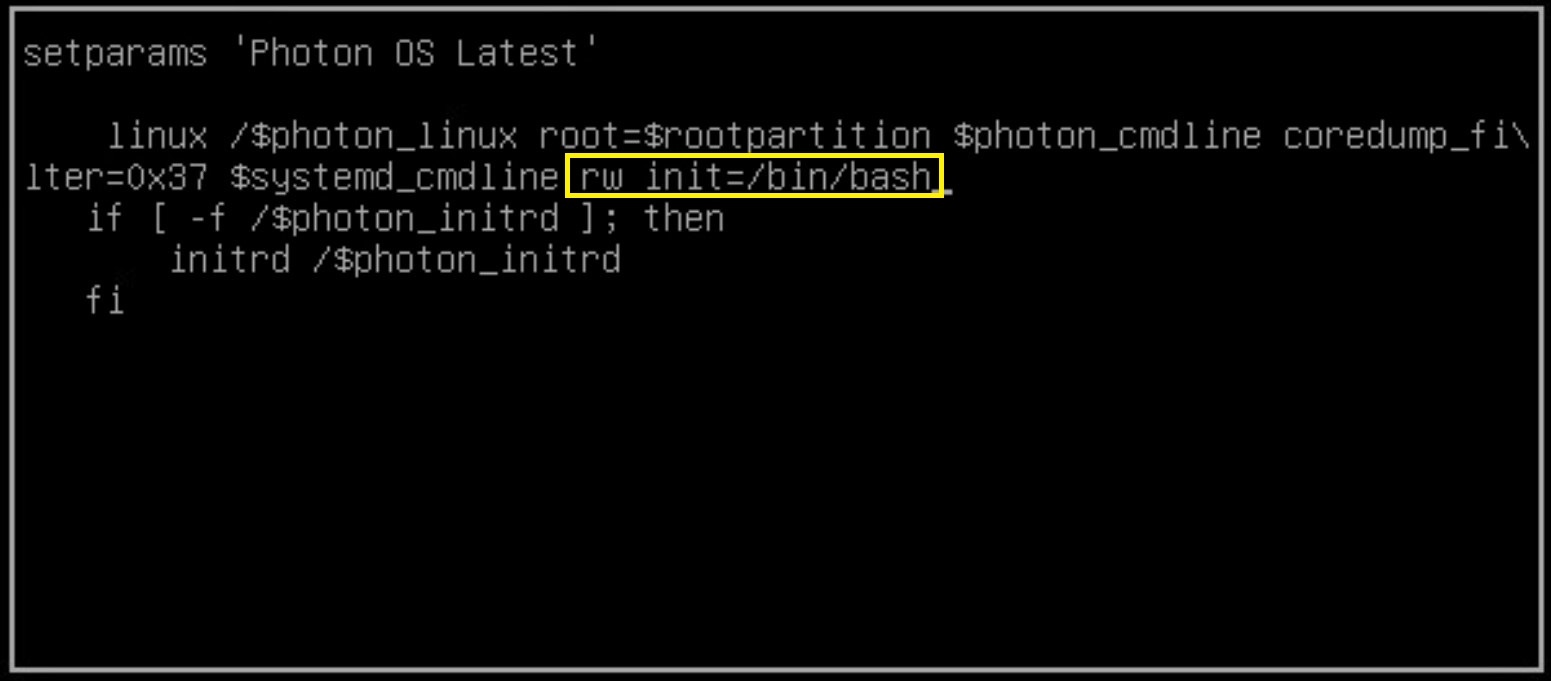
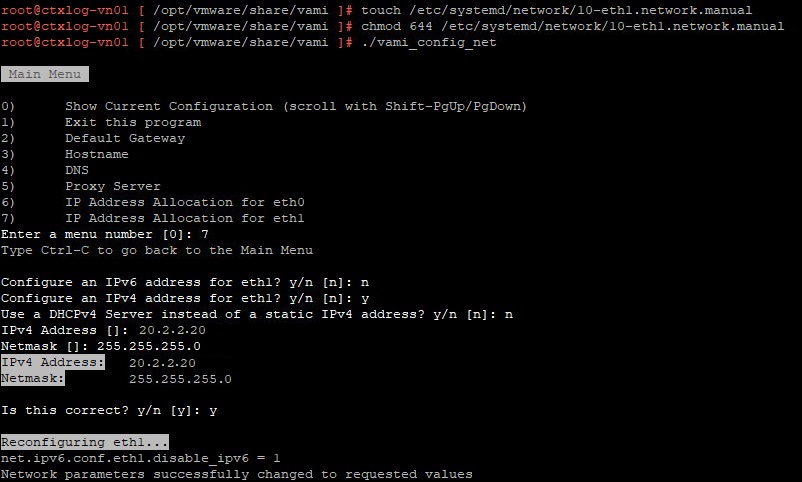
To configure the second network interface open a SSH session to vRLI appliance. Move to /opt/vmware/share/vami/ and run the network configuration script. vami_config_net. Eth1 is now also available for configuration. First select ‘0’ for a configuration overview. In the results is an error on eth1 displayed. This error keeps us from being able to configure eth1.
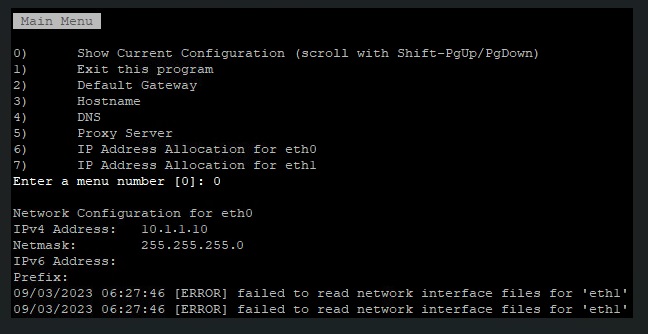
After some ‘Trial & Error’ research I noticed the following error during reconfiguring eth1 “can’t open /etc/systemd/network/10-eth1.network”
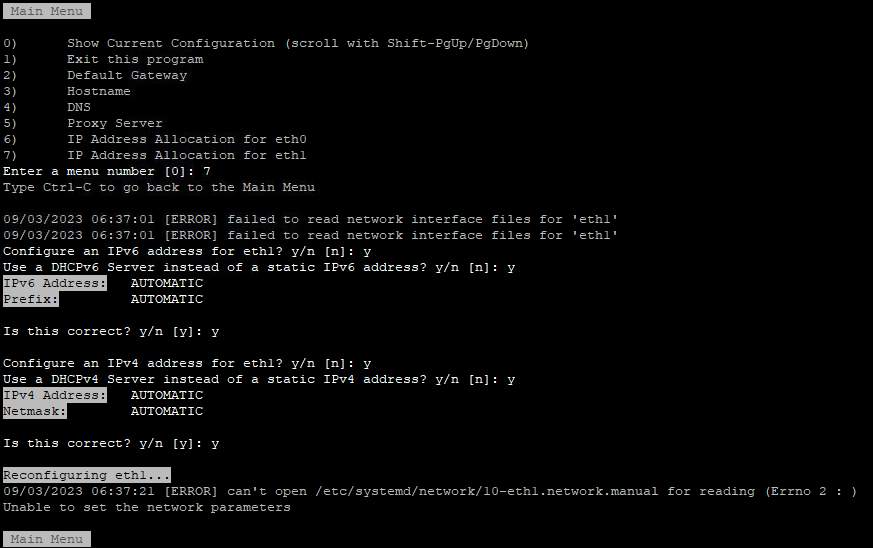
In the directory /etc/systemd/network is the file “10-eth1.network” not present. The name of the file could be different then here in this example. It depends on the number of network interfaces. I fixed this issue by creating this file manual.
- touch /etc/systemd/network/10-eth1.network
- chmod 644 /etc/systemd/network/10-eth1.network
- Config the second network interface. Go to the directory /opt/vmware/share/vami/ and run the network configution script. vami_config_net. Eth1 is now also available for configuation.
- Check the new configuration by selecting option 0. If Ok press 1 to exit
- Restart the network, systemctl restart systemd-networkd.service
Now this issue is fixed we can move on to configure the persistant static route for vRLI log forwarding.
Edit /etc/systemd/network/10-eth1.network
The file shlould look like this before editing:
[Match] Name=eth1 [Network] Gateway=10.1.1.1 Address=20.2.2.20/24 DHCP=no [DHCP] UseDNS=false
Now add route information at the end of the file:
[Match] Name=eth1 [Network] Gateway=10.1.1.1 Address=20.2.2.20/24 DHCP=no [DHCP] UseDNS=false [Route] Gateway=20.2.2.1 Destination=30.3.3.233/24
Save the file and restart the network service.
systemctl restart systemd-networkd.service
Check if the new route is present.
route -n
Test if you reach the destionation from CLI. I used Syslog over UDP port 514.
nc -v 30.3.3.233 514
Answer if configuration is working:
[30.3.3.233 514] open
The last step is to configure the vRLI Log Forwarding Destination.
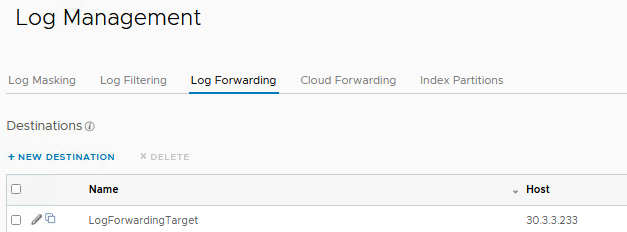
Send a test event and check if the event is received by the target.
Keep in mind that multic-nic configurations in vRLI are not officially supported.
Also credits to this blog post that pushed me in the right direction.