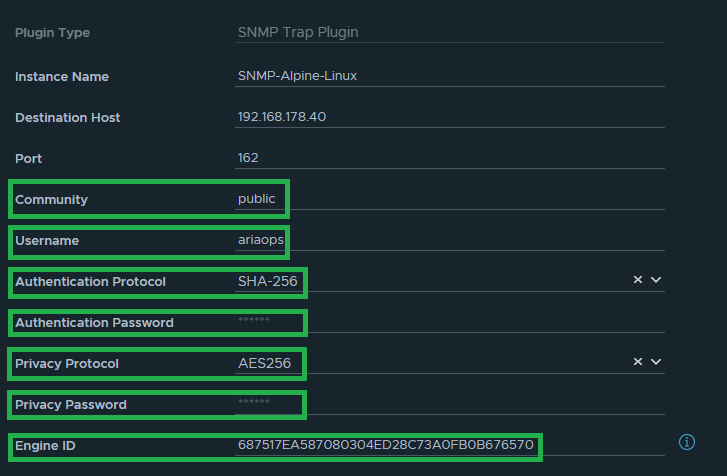
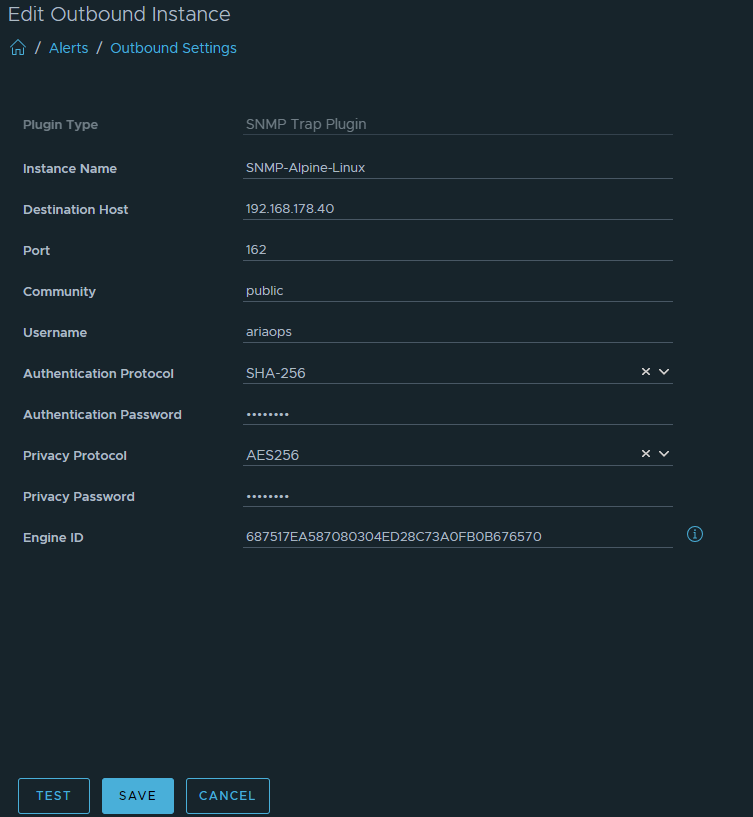
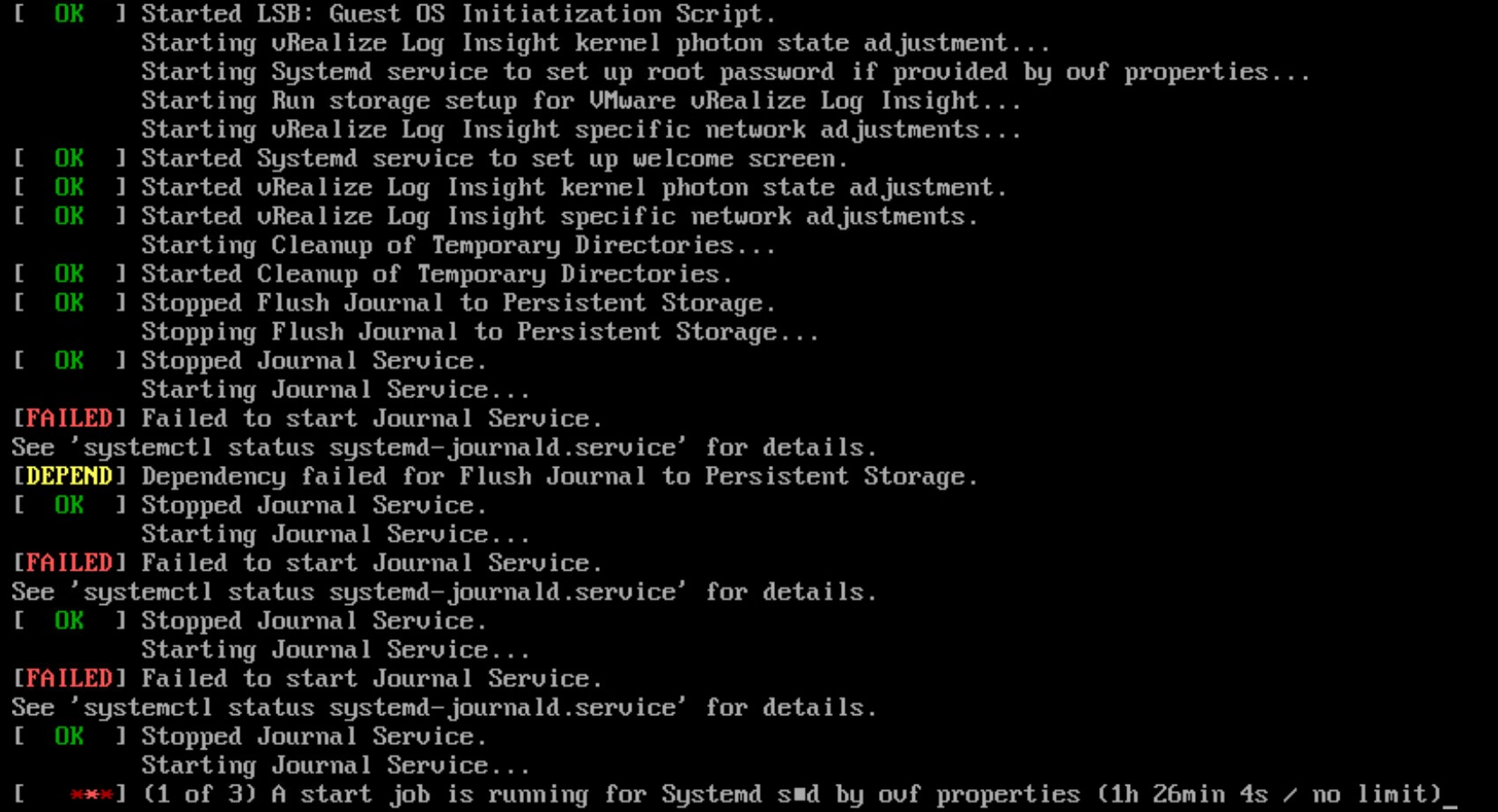
Recently, while testing after upgrading Aria Operations 8.16 to 8.17.1 Hotfix1, I found that I could not forward alerts via API to a remote monitoring system.

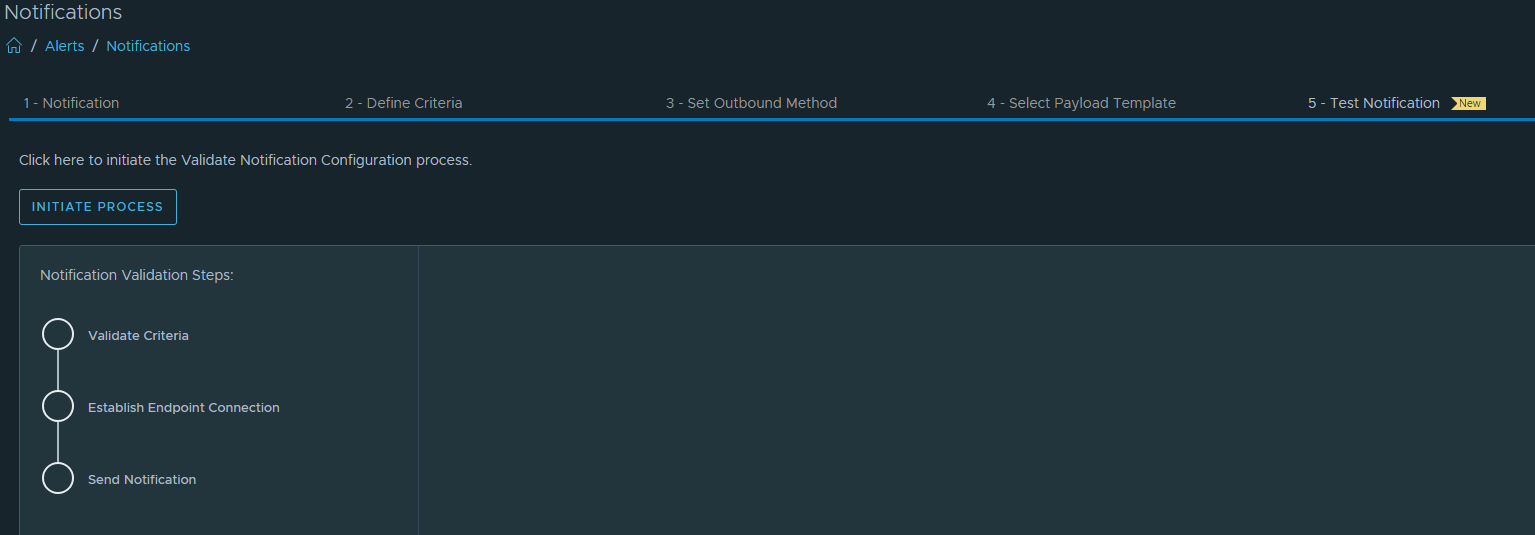
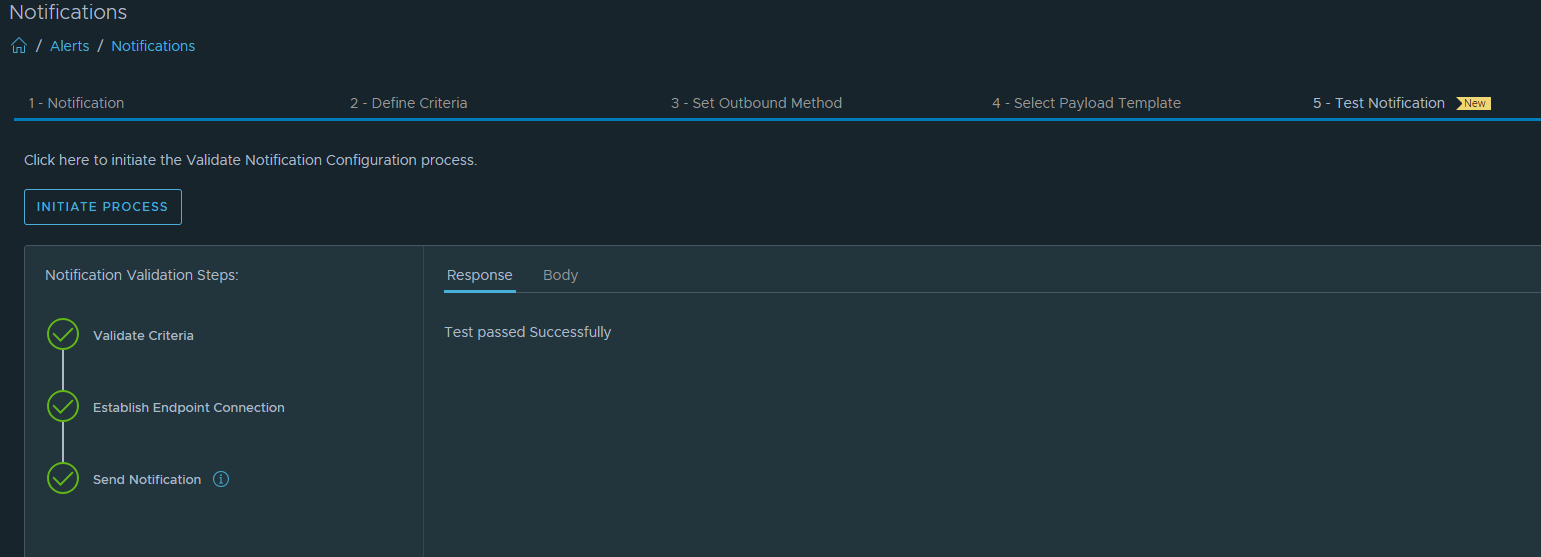
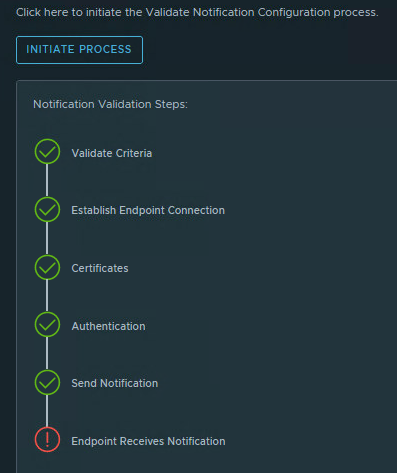
While testing an alert notification (Test Notification in a random alert). We see an error message at ‘Endpoint Receives Notification’.
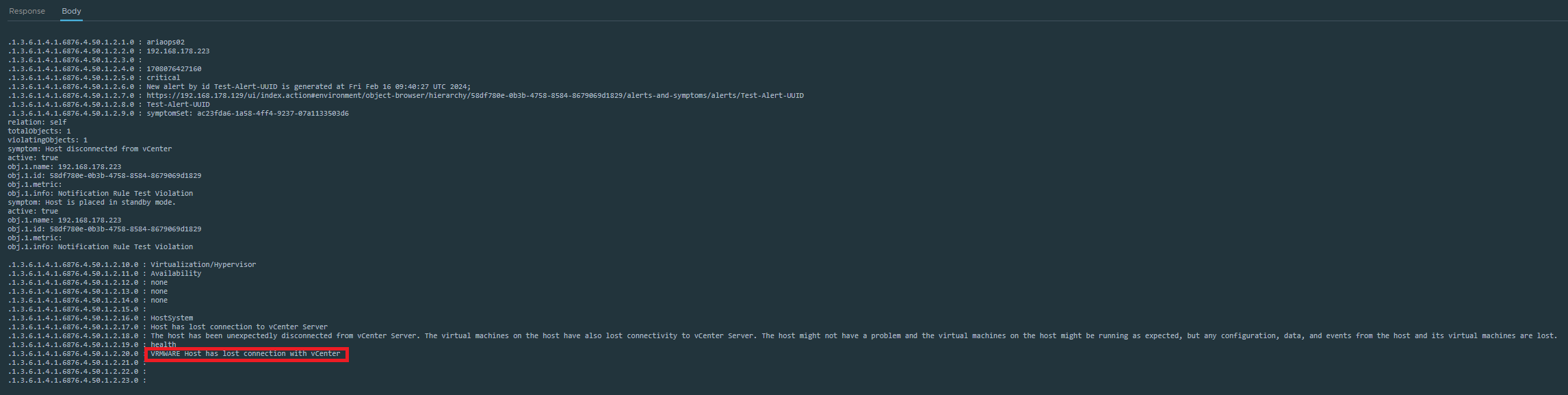
After investigation, the problem appears to be in the JSON code in the payload template. Nothing had changed here and we may be dealing with a bug here. Let’s take a look at the payload template.
Payload Template working fine in 8.16 and is broken in 8.17.1 Hotfix1
In the payload template sample, we see in the JSON code section highlighted in green that the new line character ‘\n’ is used.

Payload Template working fine in 8.17.1 Hotfix1
In the next payload template sample, we see in the JSON code section highlighted in green that the new line character ‘\n’ is not used.

After we apply another test alert notification using the payload template without the new line character “\n” everything works fine.
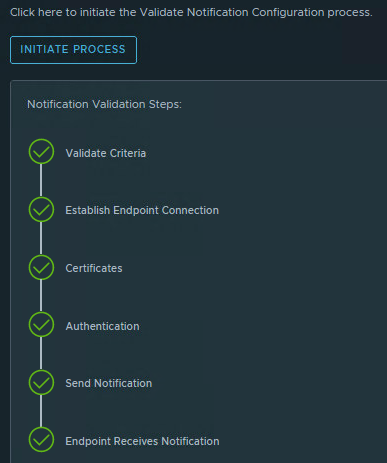
I opened a ticket by VMware/Broadcom GSS and they confirmed the bug. It is now waiting for an update that fixes this issue. As soon as there is an update I will report it here.
Update June 19:
The special character “\” json bug is fixed in Aria Operations 8.17.2. See the release notes. VMware Aria Operations 8.17.2 (broadcom.com) .
The following issues have been resolved as of Aria Operations 8.17.2:
- Snapshot age reporting incorrectly
- [App Monitoring] Product managed telegraf agent installation via script fails due to wget.exe URL is not reachable from Windows machine to CP
- Reclamation page show >0 days old snapshots with 0 GB reclaimable space
- Update Messaging in Manage Agents page
- Uninstalling ARC agent status for windows-endpoint keeps on loading state when uninstall gets triggered through api.
- Activated plugins is not shown post Agent is tried to uninstall with failed attempts
- [APP Monitoring] : vROPS Large Environment – Bootstrap operation takes 11 mins to complete for 1 VM
- Agent Installation on Windows VM taking more than 5mins
- “Manage Telegraf Agents” page takes 30 sec to load
- [APP Monitoring] : ARC services are operational on the endpoint VM; however, the agent status is currently indicated as unhealthy in vROPS UI
- NPE when sending Alert Notification
- [WLP] [vSAN] During the Workload Optimization, the VM vSAN compatibility check calls are failing, when the endpoint vCenter version is 8.0 U2 and higher
- Cost Calculation failed on one DC.
- [AWLP] [Backend] vRA calls, to get the advanced workload placement plan from vROps, fail on vROps side
- In case of Metric chart Metrics mode, for deleted object widget is throwing exception.
- Custom property: Internal server Error is thrown on alerts timeline
- Having “\” and other JSON special characters in notification template leads to invalid JSON payload.
- [Resources API Call] All resources in api response have resourceHealth and Value are GREY and -1 respectively on 8.17.x vROPs