Sometimes you run into an issue that can keep you busy for hours and afterwards the cause remains easy to solve. Recently I ran into such an issue.
There was a minor update that needs to be done. It was a VxRail code upgrade from 7.0.x to 7.0.2xx.
The upgrade was basically like all other upgrades:
- Run VxVerify
- If there are findings in the results, solve them before starting the upgrade
- Upload the desired VxRail target code
- Start the upgrade
- Done
The results of the vxVerify were fine, no issues detected.
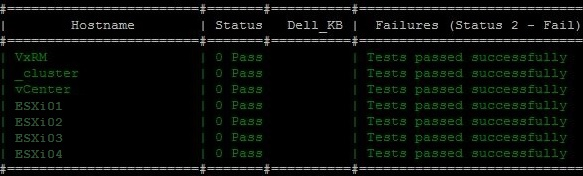
While uploading the target VxRail code everything looks fine but during the extraction of the upgrade bundle it failed at 50%. So I start a retry but the extraction of the upgrade bundle failed again at 50%. At the Cluster level we noticed the following error.
VXR1F4114 ALARM Upload of upgrade composite bundle unsuccessful VxRail Update ran into a problem… Error extracting upgrade bundle 7.0.2xx. Failed to upload bundle. Please refer to log for more details.
I opened a support request by Dell Support and in the meantime I start to examine the lcm-web.log in /var/log/mystic. I found some errors and failures but they did not lead directly to the root cause. There were errors about upgrade bundles couldn’t uploaded but those events were too general. I noticed the VxRail node that was mentioned at last in the log before the extraction failed.
Dell Support was now also working on the case. The support engineer also noted that the VxRail node I suspected was causing the problem.
I won’t go into too much detail, but at some point we checked the status of the “dcism-netmon-watchdog” service on that particular VxRail node.
[root@ESXi03:~] /etc/init.d/dcism-netmon-watchdog status
iSM is active (not running)
I had seen recently the same service status on another VxRail nodes running on code 7.0.x. Restarting the service won’t start the service. So I restarted the VxRail node. After the restart it could take some minutes before the service is restarted. I checked the service again.
[root@ESXi03:~] /etc/init.d/dcism-netmon-watchdog status
iSM is active (running)
Finally we restarted(retry) the VxRail code extraction. Both the VxRail code extraction and VxRail upgrade were successful.