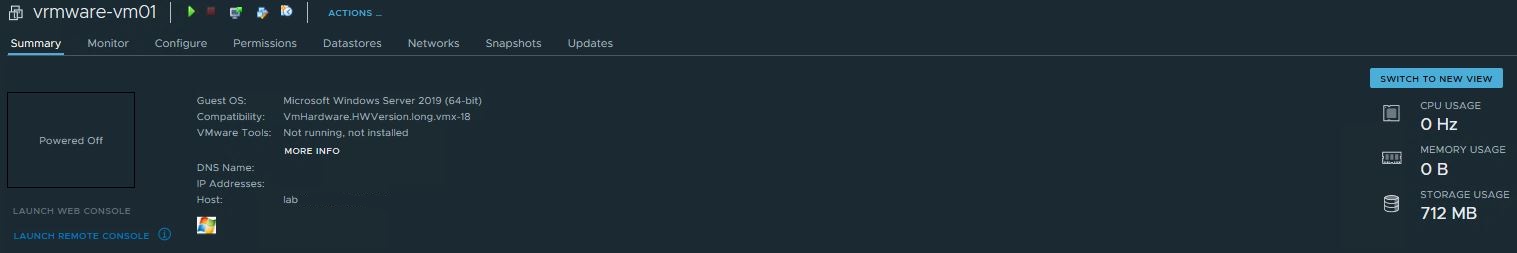Last year I wrote an blog post about the VMware vCLS datastore selection. This blog post is one of the most read articles on my website. This does indicate that there is a need to be able to choose a datastore on which the vCLS vms are placed.
Today VMware announced vSphere 7.0 update 3. In this update there is also an improvement on the vCLS datastore selection. It’s now possible to choose the datastore on which the vCLS vms should be located.
In the following video on the VMware vSphere YouTube channel move on to 20 minutes to learn more about the vCLS vms datastore selection improvement.
Another improvement is that the vCLS vms now have a unique identifier. This is useful when you have multiple clusters managed by the same vCenter.
It’s always good to see that a vendor is listening to the customers’ needs to further improve a product.
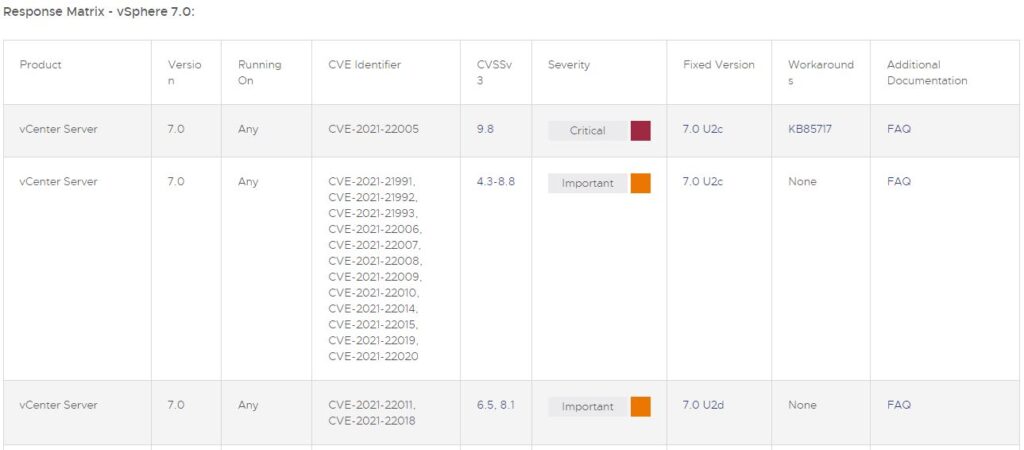
VMware has released yesterday a new security update because of a vCenter vulnerability, VMSA-2021-0020. The CVSSv3 score is 9.8. Affected vCenter versions are 6.5, 6.7 and 7.0.
You find the complete information and response matrix at the following link.
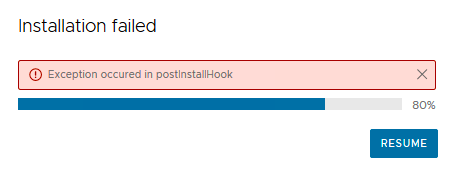
Last night I spend several hours to update the vCenter in my lab from vCSA 7.0. Update 1d to vCSA 7.0 Update 2. The update kept going wrong. I’ve staged the update package first. After staging the update was completed I started the installation. This result in the following error: Exception occured in postInstallHook.
So I tried Resume.
This seems so far so good. Continue.
Continue the Installation.
Same error again! Let’s retry Resume and Cancel in the next step.
Cancel.
Now I get stuck. So I quit to get some sleep :-).
This morning I woke up and received an e-mail from WIlliam Lam that he has written a new blog post about an error during upgrade to vCenter vCSA 7.0 Update 2, “Exception occurred in install precheck phase“. This is a different error than the error that I experienced yesterday but I have seen this error also during one of the attemps.
Here an overview of the errors during my attempts:
Exception occured in postInstallHook This error appears after staging the update and install it later
Exception occurred in install precheck phase This error appears after stage and install at the same time.
Now let’s try the workaround from William Lam that should result in a working vCenter vCSA 7.0 Update 2.
Create a snapshot of the vCSA
Stage the update file
SSH to the vCSA
Move to folder /etc/applmgmt/appliance/
Remove the file software_update_state.conf
Move to folder /usr/lib/applmgmt/support/scripts
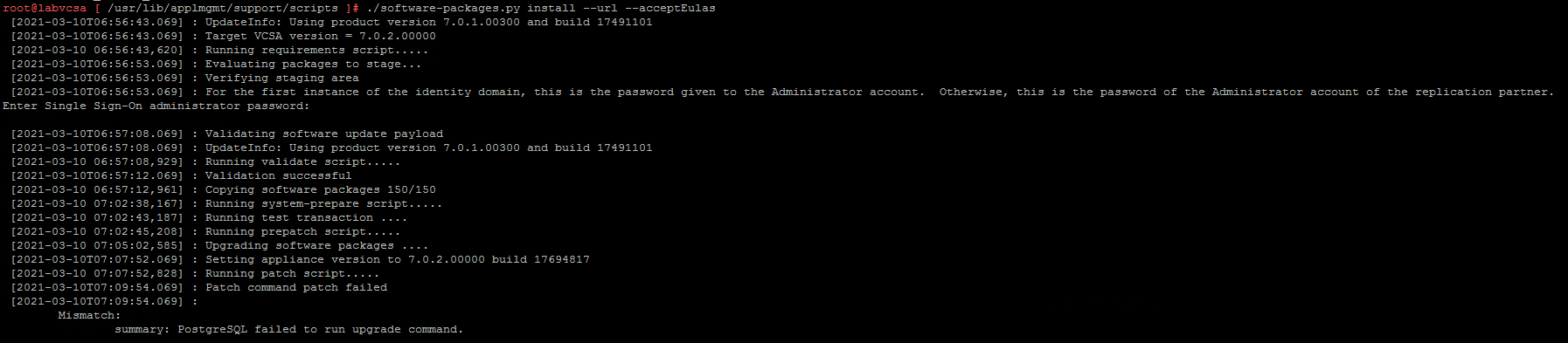
Run script ./software-packages.py install –url –acceptEulas
The update ended with an PostgreSQL error and vCenter is not working after the update. I rebooted the appliance one more time without any result.
Conclusion:
vCenter vCSA 7.0 Update 2 is in my opinion not ready for deployment at this moment. I rollback the snapshot and decide to wait for an updated version of vCenter vCSA 7.0 Update 2.
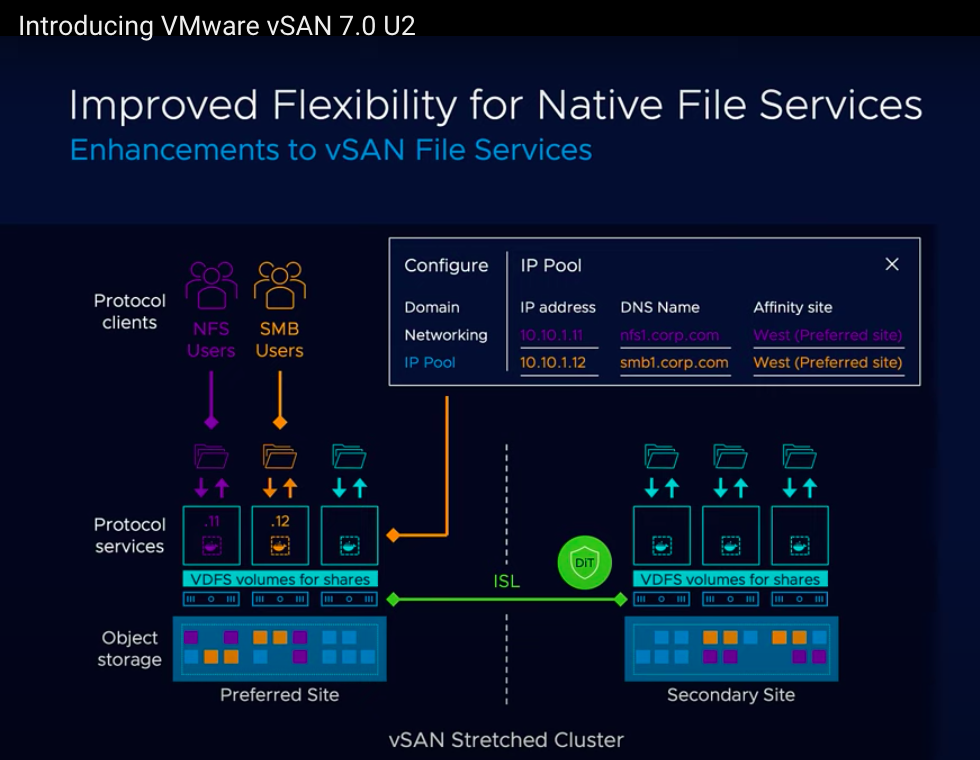
Today Duncan Epping posted this video “Introducing VMware vSAN 7.0 U2”.
Since the introduction, I am a fan of VMware vSAN Native File Services. With the introduction of vSAN 7.0 Update 2, vSAN Native File Services is also available for stretched vSAN clusters. How cool is that!
vSphere 7.0 Update 2 is already available for download.
Recently I updated the vCenter appliance in my lab to version vCSA 7.0 update 1d. After updating I was clicking a bit through the environment. By coincidence I saw the following button when I opened the summary page of a VM.
Curious as I am, I clicked the button. But first the regular view below. This view, which everyone knows, is now called the classic view.
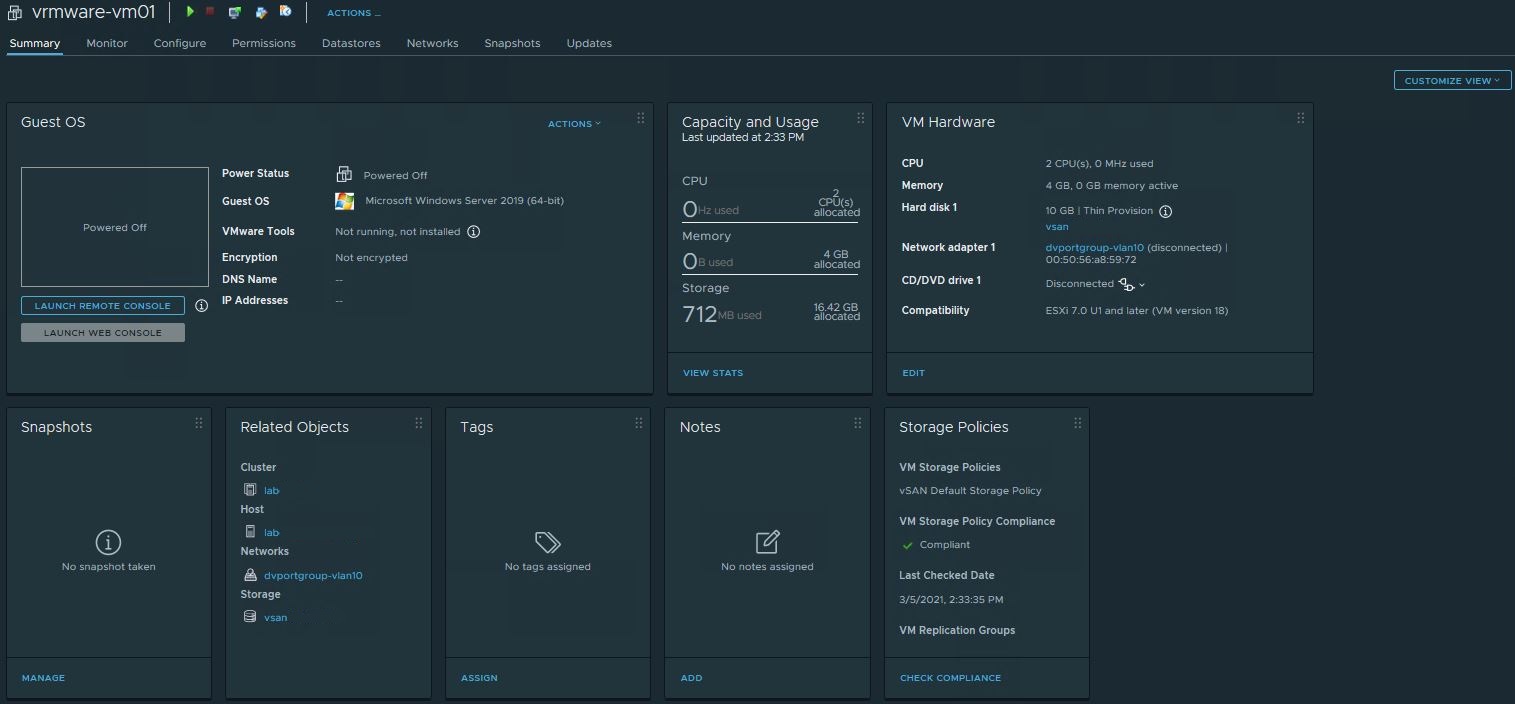
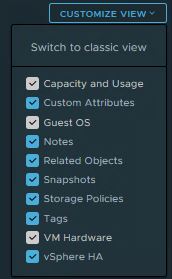
After clicking the “Swith To New View” button an customize view will appear.
What immediately stands out is the fresh widget view. It’s a small change, but I’m a fan of it right away. I been wondering ever since when this view was introduced. I searched the VMware documentation but I cannot find it. It is certainly not available in versions prior to vCenter vCSA 7. Maybe it has been available for a while but I haven’t noticed it before.
If you still prefer the classic view. You can just as easily switch back to your old trusted view.
You can easily adjust what you want to see and what not. If you know when this customize view was introduced, please leave a comment.
In the past years, I have experienced some vSAN performance issues due to faulty hardware. The goal was to know at an early stage whether there are hardware errors that can lead to performance degradation.
One problem I’ve seen a few times are hardware related problems that lead to a high latency, outstanding io’s and congestions at the backend storage. I was wondering if it is possible to spot these kinds of issues earlier? I started searching in vRealize Log Insight.
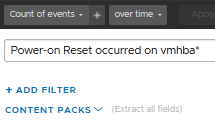
I found some events afterwards during my research. In the period prior to the performance issues, many “Power-on Reset on vmhba” messages had been written in the vobd.log and vmkernel.log. At first it was a few events per day, but as time passed the frequency with which the events came increasingly higher and finally led to a very poor vSAN performance.
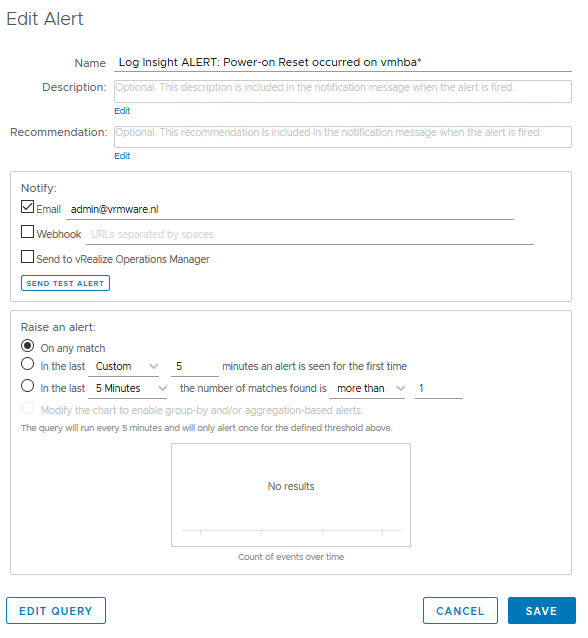
In the following steps I will explain how you can define an email alert in vRealize Log Insight that helps to detect this kind of issues at an early stage. Now it’s possbile to take early action to avoid potential problems.
Step 1. Create a query that search for “Power-on Reset occurred on vmhba” events
Recently VMware has rebranded their customer portal “My VMware” to “Customer Connect”. One of the cool new features which I really appreciate is the app launcher. For example, you can add Skyline to the app launcher, so you can go directly to Skyline (SSO) after logging into Customer Connect. Follow the next steps to add Skyline to VMware apps.
Step1. Login to VMware Customer Connect and select the Customize button
Step2. Select VMware Apps and add VMware Skyline to My Apps
Step 3. Done. You have added VMware Skyline to VMware apps.
When you go back to home or log in again the next time you will see VMware Skyline in your apps and you can go directly to Skyline.
It had been a while since I have installed a non HCI VMware cluster. After installing the ESXi hosts, the updates and multipath software were installed. The storage team has made the datastores available. Nothing special. After installation, the host has been taken out of maintenance mode. Then there was an error “Error: “Cannot install the vCenter Server agent service. Unknown installer error“. See VMware KB #2083945 and VMware KB #2056299.
I have followed all standard procedures to resolve HA errors:
Right click the affected host. Reconfigure for vSphere HA
Reconfigure HA on a cluster level. Turn Off vSphere HA and Turn ON vSphere HA
Disconnect and reconnect the affected host
After performing the above options, the issue was still unsolved. Next I wanted to know if the HA (fdm) agent is installed or not. I ssh to the host and ran the following command:
Esxcli software vib list | grep fdm
The output was empty. I realized that the HA agent was not installed. In VMware KB #2056299 is written about a vib dependency. That made me realize that besides the VMware updates also multipath software was installed, Dell EMC PowerPath/VE. This turned me out to the right direction to solve the problem.
Solution:
Ssh to the affected host(in maintenance mode)
Esxcli software vib list or Esxcli software vib list | grep power. The results are three vibs: powerpath.plugin.esx, powerpath.cim.esx and powerpath.lib.esx
Uninstall the three vibs running the following command: esxcli software vib remove –vibname=powerpath.plugin.esx –vibname=powerpath.cim.esx –vibname=powerpath.lib.esx
Reboot the host
Esxcli software vib list | grep power The output shlould be empty.
Leaving maintenance mode. The HA agent is now installing. After the HA agent is installed enter maintenance mode again
Esxcli software vib list | grep fdm The output should be similar like: vmware-fdm VMware VMwareCertified 2021-02-16
Reinstall Dell EMC PowerPath/VE. Installing the same version PowerPath/VE gave a VUM error even after restarting the host. To resolve this error I’ve installed a newer version of PowerPath/VE. This version was installed succesful.
Leaving maintenance mode
In my case the PowerPath/VE vibs dependecies were causing the issue. Another dependency can also cause this problem. I am aware that looking for the right dependence can be a difficult job. I hope I have at least been able to help you start the search in the right direction.
November 2022. An update about this issue can be read here.
For many years I have used Veeam Management Pack for VMware to monitor the VMware environments. After the switch to vROPS I never really missed it. However, whenever an ESXi host was in maintenance, there was an option that I could not find in vROPS. It’s such a small thing that makes you think “I still have to do something with that”. What it is? If an ESXi host is in maintenance, I don’t want any alerts from this host.
Recently, a colleague pointed me to an article that offers a solution to this problem. It is actually a very simple solution that only needs to be configured once. Because the article was already several years old, I have rewritten it based on the most recent version vROPS 8.2.x.
Use Case – An administrator wants to disable alerts on a ESXi host which has been put into maintenance mode in vCenter. This to avoid any alerts from this ESXi host inside of vROPS, while the admin wants to continue to collect metrics from this ESXi host. Goal– Do this automatically without any manual changes in vROPS. As soon as a host is in maintenance mode in vCenter, vROPS should be aware of this and should stop alerting on the host in vROPS. Solution – This can be achieved by a one time configuration using Custom Groups and Policy.
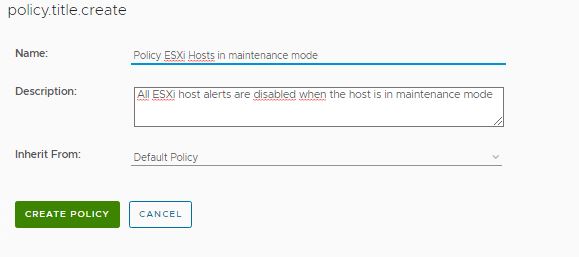
1- Create a new policy in vROPS named “Policy ESXi Hosts in maintenance mode”. This policy can be created under the default policy. Go to Administration -> Policies -> Add 2- Select the default policy and click on the Add symbol to add a new policy. 3- Give it a name and description as shown below.
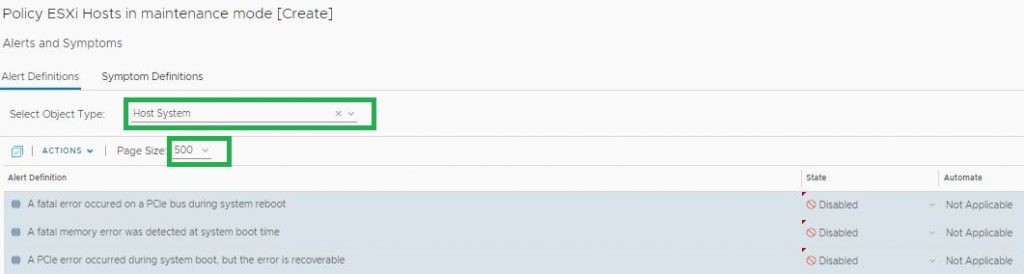
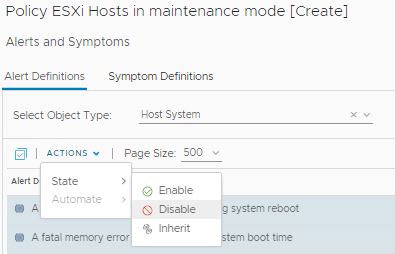
4- Click on Alerts and Symptom Definitions and filter the list of alerts with only host system alerts. We want a filtered list so that we can disable these in one go.
5- Now press CTRL + A on the keyboard to select all of them, you can also click on Actions -> Select All. 6- Click on Actions – > State -> Disable
7- Click on Save and now you can see he new policy under your default policy.
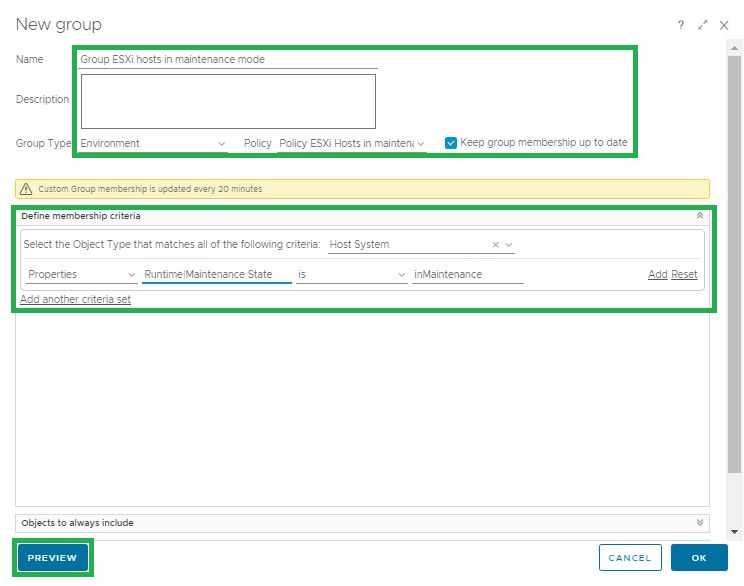
8- Create a new custom group named “Group ESXi hosts in maintenance mode”. Use the following criteria to dynamically add members to this custom group based on ESXi host property which vROPS collects every few minutes. Click on Environment -> Custom Groups -> Click on Add to add a new custom group. Make sure to select the policy “Policy ESXi hosts in maintenance mode” which we created earlier.
9- Click on Preview to see if you are getting results. If there is any host in maintenance mode it will be displayed in the preview.
10 – Finally go into Administration -> Policies -> Active Policies and set the newly created policy at priority 1.
Now, as soon as you will put an ESXi host into maintenance mode in vCenter, within a few minutes it will be discovered as a ESXi host in maintenance in vROPS. It will be added to the new created custom group “Group ESXi hosts in maintenance mode”. Now all the alerts from this ESXi hosts are disabled. You will not see any alerts as long it is in maintenance mode.
Once the ESXi host is out of maintenance mode it will be moved out of the custom group. Do note, that if you add any new alerts in the future, related to hosts, you would need to make sure that they are disabled in this policy.
Recently I noticed that after updating a VMware vCenter from 6.7 to 7.0 u1 the new VMware vCLS VMs where placed on datastores that are not meant for VMs.
Starting with vSphere 7.0 Update 1, vSphere Cluster Services (vCLS) is enabled by default and runs in all vSphere clusters. vCLS ensures that if vCenter Server becomes unavailable, cluster services remain available to maintain the resources and health of the workloads that run in the clusters.
The datastore for vCLS VMs is automatically selected based on ranking all the datastores connected to the hosts inside the cluster. A datastore is more likely to be selected if there are hosts in the cluster with free reserved DRS slots connected to the datastore. The algorithm tries to place vCLS VMs in a shared datastore if possible before selecting a local datastore. A datastore with more free space is preferred and the algorithm tries not to place more than one vCLS VM on the same datastore. You can only change the datastore of vCLS VMs after they are deployed and powered on.
You can perform a storage vMotion to migrate vCLS VMs to a different datastore.
If you want to move vCLS VMs to a different datastore or attach a different storage policy, you can reconfigure vCLS VMs. A warning message is displayed when you perform this operation.
Conclusion: If datastores used that are intended for e.g. repository purposes, it is possible that the vCLS files are placed on that datastores. You can tag vCLS VMs or attach custom attributes if you want to group them separately.